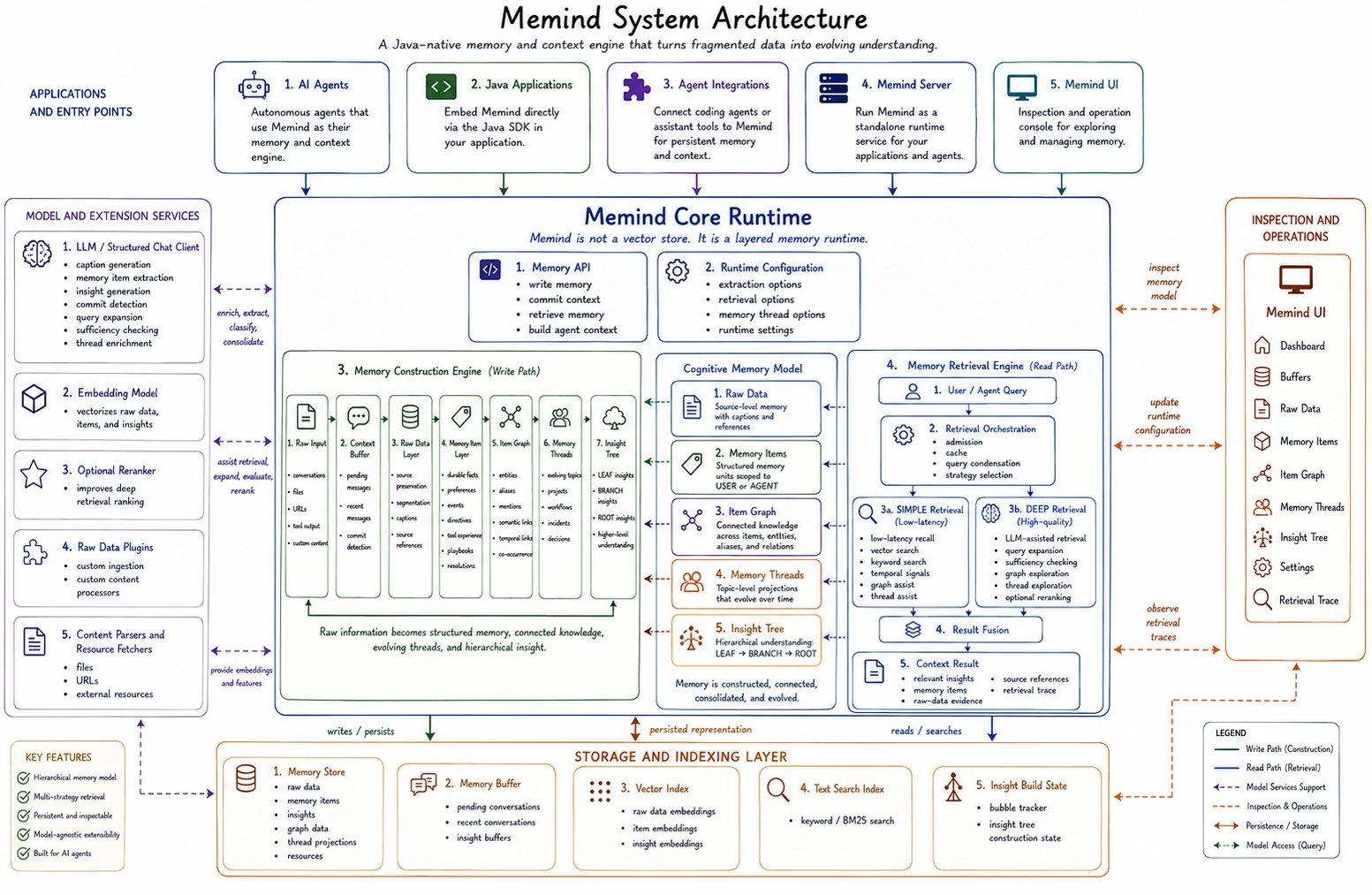

memind-server. Memind UI sits beside the runtime as an inspection and operation console.
At a high level, the system has six major parts:
| Part | Role |
|---|---|
| Applications and entry points | AI agents, Java applications, agent integrations, memind-server, and Memind UI connect to Memind. |
| Memind Core Runtime | The central runtime that owns memory writing, context commit, retrieval, runtime configuration, and lifecycle. |
| Memory Construction Engine | The write path that turns raw input into layered memory. |
| Cognitive Memory Model | The memory layers built by Memind: Raw Data, Memory Items, Item Graph, Memory Threads, and Insight Tree. |
| Memory Retrieval Engine | The read path that searches across memory layers and returns concise context. |
| Storage, indexing, and model services | Persistent storage, buffers, vector indexes, text search, LLMs, embeddings, rerankers, parsers, and plugins. |
Applications and entry points
Memind can be used in multiple ways. Java applications can embed Memind directly as a library through the Java SDK. Agent integrations can connect coding agents or assistant tools to a Memind runtime.memind-server exposes Memind as a standalone service. Memind UI provides an interface for inspecting and operating the memory system.
All of these entry points eventually connect to the same core idea: a Memory runtime that can write memory, commit context, retrieve memory, and build agent context.
Memind Core Runtime
Memind Core Runtime is the center of the system. It contains four main areas:| Runtime area | Purpose |
|---|---|
| Memory API | Provides the main operations for writing memory, committing buffered context, retrieving memory, and building context windows. |
| Runtime Configuration | Controls extraction behavior, retrieval behavior, memory-thread behavior, and runtime settings. |
| Memory Construction Engine | Handles the write path from raw input to structured and consolidated memory. |
| Memory Retrieval Engine | Handles the read path from user or agent query to retrieved context. |
memind-server.
Memory Construction Engine
The Memory Construction Engine is the write path. It progressively transforms raw fragmented information into structured, connected, and consolidated memory.LEAF, BRANCH, and ROOT insights.
This pipeline is the core reason Memind is more than a flat memory store.
Cognitive Memory Model
The Cognitive Memory Model is the layered memory structure produced by Memind.Memory Retrieval Engine
The Memory Retrieval Engine is the read path. When an agent asks a question, Memind does not only search a vector index. It can retrieve across multiple memory layers, including insights, memory items, raw-data evidence, graph connections, and memory threads.SIMPLE retrieval is optimized for low-latency recall. It can combine vector search, keyword search, temporal signals, graph assist, thread assist, and result fusion.
DEEP retrieval is designed for harder queries. It can use LLM-assisted retrieval, query expansion, sufficiency checking, graph exploration, thread exploration, and optional reranking.
The final context result can include relevant insights, memory items, raw-data evidence, source references, and retrieval trace information.
Storage and indexing layer
Memind separates runtime memory from storage and indexes. The storage and indexing layer supports both construction and retrieval:| Component | Role |
|---|---|
| Memory Store | Persists raw data, memory items, insights, graph data, thread projections, and resources. |
| Memory Buffer | Holds pending conversations, recent conversations, and insight build buffers. |
| Vector Index | Stores embeddings for raw data, memory items, and insights. |
| Text Search Index | Supports keyword and BM25-style search. |
| Insight Build State | Tracks state used to construct and reorganize the Insight Tree. |
Model and extension services
Memind uses model services and extension points around the core runtime. The LLM or structured chat client is used for tasks such as caption generation, memory item extraction, insight generation, commit detection, query expansion, sufficiency checking, and thread enrichment. The embedding model vectorizes raw data, memory items, and insights. An optional reranker can improve deep retrieval ranking. Raw Data plugins, content parsers, and resource fetchers extend what Memind can ingest and how content enters the memory construction pipeline. These services support the runtime, but they are not the memory system by themselves. The memory system is the layered runtime that organizes their outputs into durable, connected, and inspectable memory.Inspection and operations
Memind UI makes the memory runtime inspectable. It lets developers inspect dashboard state, buffers, Raw Data, Memory Items, the Item Graph, Memory Threads, the Insight Tree, settings, and retrieval traces. This is important because agent memory should not be a black box. Developers need to see what was stored, how it was extracted, how it was connected, what was consolidated, and why certain context was retrieved.Why this architecture matters
Memind is designed around one principle:Memory is constructed, connected, consolidated, and evolved.A simple vector store can retrieve similar text. Memind is built to preserve source context, extract structured memory, connect related knowledge, follow long-running topics, build higher-level insights, and return useful context to agents. That is why the center of the architecture is not a database or an index. It is the Memind Core Runtime.