Overview
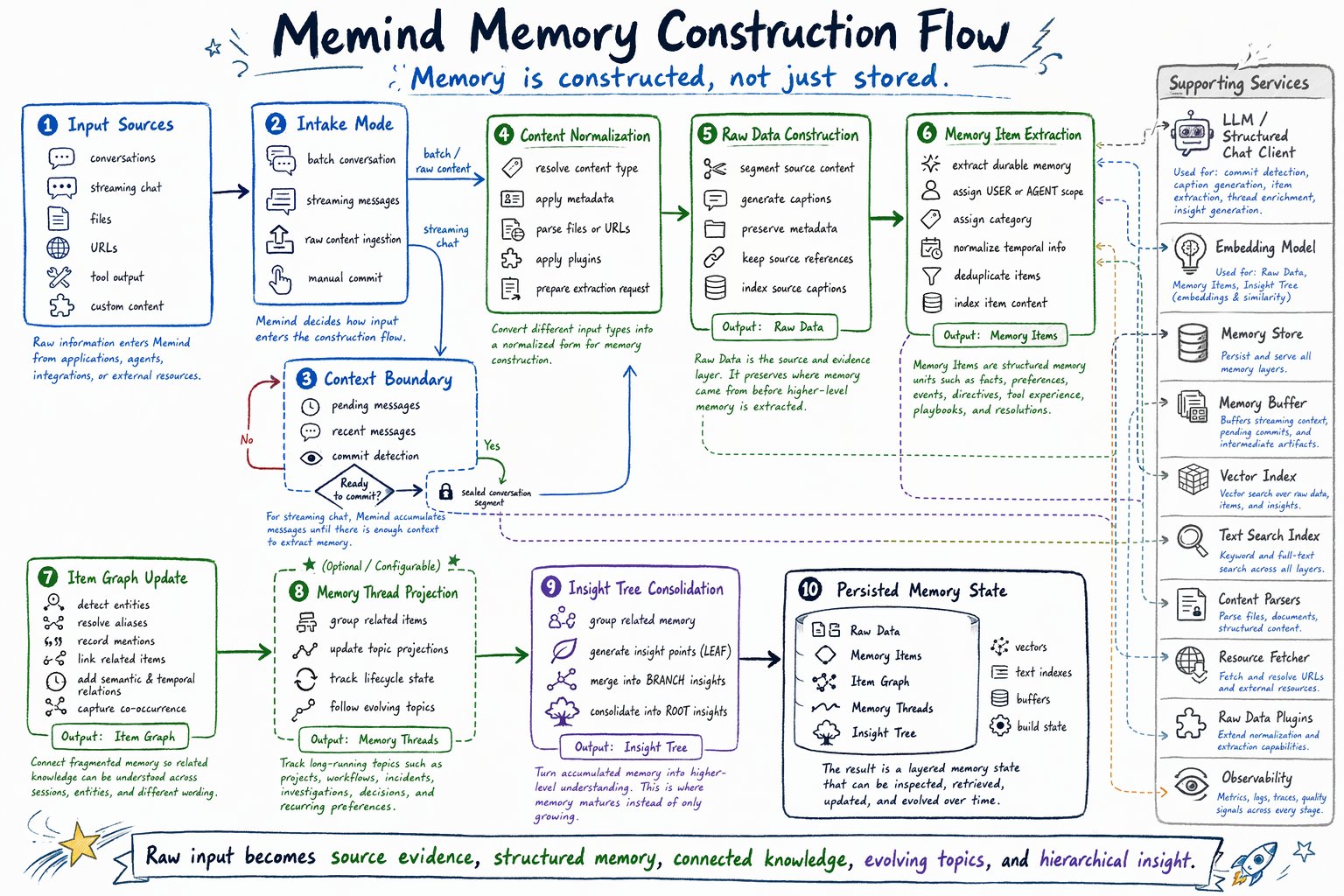
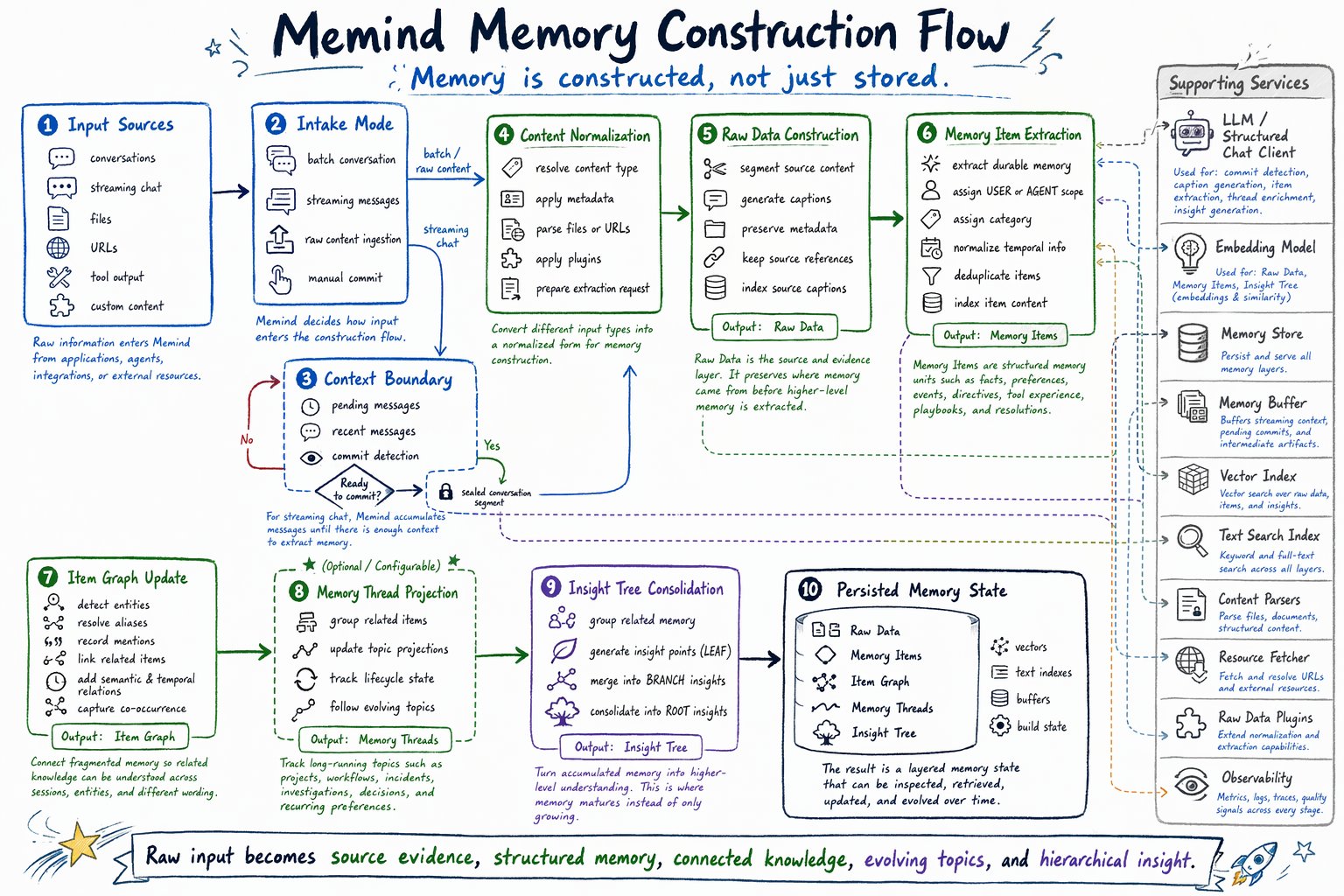
Memind does not treat memory as a list of text snippets. When new information enters the system, Memind progressively transforms it into a layered memory state: Raw input -> context boundary -> normalized content -> Raw Data -> Memory Items -> Item Graph -> Memory Threads -> Insight Tree Each stage adds a different kind of structure.| Stage | Main responsibility |
|---|---|
| Input Sources | Receive conversations, streaming messages, files, URLs, tool output, or custom content. |
| Intake Mode | Decide how the input enters the construction flow. |
| Context Boundary | Buffer streaming chat and decide when enough context is ready to extract. |
| Content Normalization | Convert different input types into a normalized extraction request. |
| Raw Data Construction | Preserve source-level evidence with segments, captions, metadata, and references. |
| Memory Item Extraction | Extract durable structured memory units. |
| Item Graph Update | Connect related memory through entities, aliases, mentions, and item links. |
| Memory Thread Projection | Track long-running topics as evolving projections. |
| Insight Tree Consolidation | Consolidate memory into higher-level LEAF, BRANCH, and ROOT insights. |
| Persisted Memory State | Store layered memory so it can be inspected, retrieved, updated, and evolved. |
Input sources
Memory construction starts with raw information. Typical input sources include:- conversation messages
- streaming chat messages
- files
- URLs
- tool output
- custom application content
memind-server, or other systems that write memory into Memind.
At this point, Memind has not decided what should become durable memory. The input is still raw material.
Intake mode
Memind supports different intake modes because applications produce memory in different ways.| Intake mode | When to use it |
|---|---|
| Batch conversation | When you already have a complete conversation segment ready for extraction. |
| Streaming messages | When messages arrive one at a time in a chat or agent loop. |
| Raw content ingestion | When the input is a file, URL, tool output, or custom content type. |
| Manual commit | When the application wants to force the current buffered conversation into memory. |
Context boundary
For streaming chat, extracting memory from every single message is usually too noisy. A single message may not contain enough context. It may depend on previous turns, or it may only become meaningful once the user and agent finish a small topic. Memind uses a context boundary stage to handle this. The runtime keeps:- pending messages
- recent messages
- source metadata
- conversation context
When is there enough context to extract memory?Applications can also commit manually when they already know a conversation boundary has been reached.
Content normalization
After Memind has an input segment, it normalizes the content before construction begins. Content normalization prepares different input types for the same memory pipeline. This stage can include:- resolving the content type
- applying metadata
- parsing files or URLs
- fetching external resources
- applying raw-data plugins
- preparing an extraction request
Raw Data construction
Raw Data is the source and evidence layer. Before Memind extracts higher-level memory, it preserves the original source context in a more inspectable form. Raw Data construction can include:- segmenting source content
- generating captions
- preserving metadata
- keeping source references
- indexing source captions
What source information did Memind observe?It is not the final memory layer. It is the source layer that makes the rest of the memory system inspectable.
Memory Item extraction
Memory Items are structured units of durable memory. After Raw Data is built, Memind extracts memory items from the source segments. A Memory Item may represent:- a user fact
- a preference
- an event
- a durable directive
- tool experience
- a reusable playbook
- a resolved problem
- optional foresight
USERorAGENTscope- memory category
- content type
- source reference
- temporal information
- vector index information
What durable memory should be kept from the source?Memory Items are the foundation for later layers. The Item Graph, Memory Threads, Insight Tree, and Retrieval all depend on useful structured items.
Item Graph update
The Item Graph connects fragmented memory. Without a graph, memory items remain isolated. An agent may know several facts, but still fail to understand how they relate. The Item Graph update stage connects items through signals such as:- entities
- aliases
- mentions
- semantic links
- temporal links
- causal links
- co-occurrence
How are these memory items related?The Item Graph is one of the main reasons Memind can move beyond flat fact storage.
Memory Thread projection
Memory Threads track long-running topics. Some memory should not be understood as isolated facts. Projects, workflows, incidents, investigations, decisions, and recurring preferences often span many sessions and many memory items. Memory Thread projection groups related items into evolving topic-level projections. A thread can represent:- a project
- a workflow
- an incident
- an investigation
- a decision path
- a recurring user preference
- a repeated agent behavior
What ongoing topic does this memory belong to?This layer is configurable. Depending on runtime settings, Memory Threads may be enabled or disabled, and thread derivation may run synchronously or asynchronously.
Insight Tree consolidation
The Insight Tree is the consolidation layer. As memory grows, simply storing more items is not enough. The system needs a way to mature memory into higher-level understanding. Memind consolidates related memory into an Insight Tree:LEAFinsights summarize local groups of memory.BRANCHinsights combine patterns across groups.ROOTinsights represent broader understanding.
- grouping related memory
- generating insight points
- building
LEAFinsights - merging into
BRANCHinsights - consolidating into
ROOTinsights - reorganizing the tree as memory changes
What higher-level understanding can be derived from accumulated memory?This is where Memind turns memory growth into memory evolution.
Persisted memory state
The output of Memory Construction is a layered memory state. It can include:| Layer | Persisted state |
|---|---|
| Raw Data | Source segments, captions, metadata, source references. |
| Memory Items | Structured memory units, scopes, categories, timestamps, source references. |
| Item Graph | Entities, aliases, mentions, item links, and relationship signals. |
| Memory Threads | Topic projections, memberships, lifecycle state, and thread history. |
| Insight Tree | Insights, insight points, tiers, parent-child relationships, and build state. |
| Indexes | Vector indexes and text-search indexes used by retrieval. |
| Buffers | Pending conversation buffers, recent conversation buffers, and insight build buffers. |
Supporting services
Several services support the construction pipeline.| Service | Used for |
|---|---|
| LLM / Structured Chat Client | Commit detection, caption generation, memory item extraction, thread enrichment, and insight generation. |
| Embedding Model | Vectorizing Raw Data captions, Memory Items, and Insights. |
| Memory Store | Persisting Raw Data, Memory Items, Insights, graph data, thread data, and resources. |
| Memory Buffer | Holding pending conversations, recent conversations, and insight build buffers. |
| Vector Index | Searching embedded memory layers. |
| Text Search Index | Supporting keyword and BM25-style search. |
| Content Parsers | Parsing files or other structured content. |
| Resource Fetcher | Fetching URL or external resources. |
| Raw Data Plugins | Extending ingestion for custom content types. |
| Observability | Tracing and debugging construction behavior. |