Overview
Memind retrieval is designed to assemble useful agent context, not just return similar text. Many memory systems use a simple retrieval path:| Strategy | Latency profile | Best for | Main idea |
|---|---|---|---|
SIMPLE | Millisecond-level latency | Low-latency agents, chatbots, and frequent memory injection. | Multi-channel retrieval and fusion without the heavier deep reasoning path. |
DEEP | Second-level latency | Complex questions, high-quality retrieval, and workflows that can trade latency for completeness. | Sufficiency checking, query expansion, graph/thread assist, and optional |
SIMPLE when memory should feel instant.
Use DEEP when memory should be more complete.
Both strategies can retrieve across multiple memory layers:
- Insight Tree for high-level understanding
- Memory Items for structured facts, events, directives, playbooks, and resolutions
- Raw Data captions for source-level context
- Item Graph for related entities and relationships
- Memory Threads for long-running topics and project context
- Temporal signals for time-aware retrieval
Why top-k memory retrieval breaks down
Most memory systems eventually hit the same retrieval problems.| Problem | What happens |
|---|---|
| Semantic-only recall misses exact terms | A query about a tool name, class name, API, or project term may not retrieve the right memory. |
| Top-k returns fragments | The agent receives isolated facts but not the surrounding context. |
| Long-running topics get split apart | Related memories from the same project, workflow, or incident are not retrieved together. |
| Time-sensitive questions are weak | A query like “what did we decide last week?” is treated like a normal semantic query. |
| High-level understanding is missing | The agent retrieves what was said, but not what the system has learned. |
| Retrieval is hard to debug | Developers cannot see why a memory was returned or missed. |
Layered retrieval
Memind retrieval is layered retrieval. It searches what was stored, what was understood, where it came from, how it connects, and when it happened.| Layer | What it contributes |
|---|---|
| What was understood | Insight Tree returns stable patterns, preferences, and higher-level understanding. |
| What was stored | Memory Items return concrete facts, events, directives, playbooks, and resolutions. |
| Where it came from | Raw Data captions return source-level context behind retrieved memories. |
| How it connects | Item Graph and Memory Threads return related entities, relationships, topics, and project context. |
| When it happened | Temporal signals help when the query depends on recency or time constraints. |
Similarity search finds related text. Memind retrieval assembles usable agent context.
Same query, different retrieval
Consider this query:What should I remember before writing the next Memind docs page?A typical vector-memory system may return fragments:
SIMPLE retrieval can return a context package:
DEEP retrieval can investigate further when the initial context is not enough:
Retrieval strategies at a glance
Memind exposes two main retrieval strategies.| Strategy | Use it when | What it optimizes for |
|---|---|---|
SIMPLE | The query is direct and latency matters. | Fast recall with strong multi-channel coverage. |
DEEP | The query is complex, ambiguous, or needs broader context. | Higher-quality context through reasoning-assisted retrieval. |
- Start with
SIMPLEfor normal agent turns. - Use
DEEPwhen the query needs stronger recall, better evidence, or cross-session reasoning.
SIMPLE retrieval
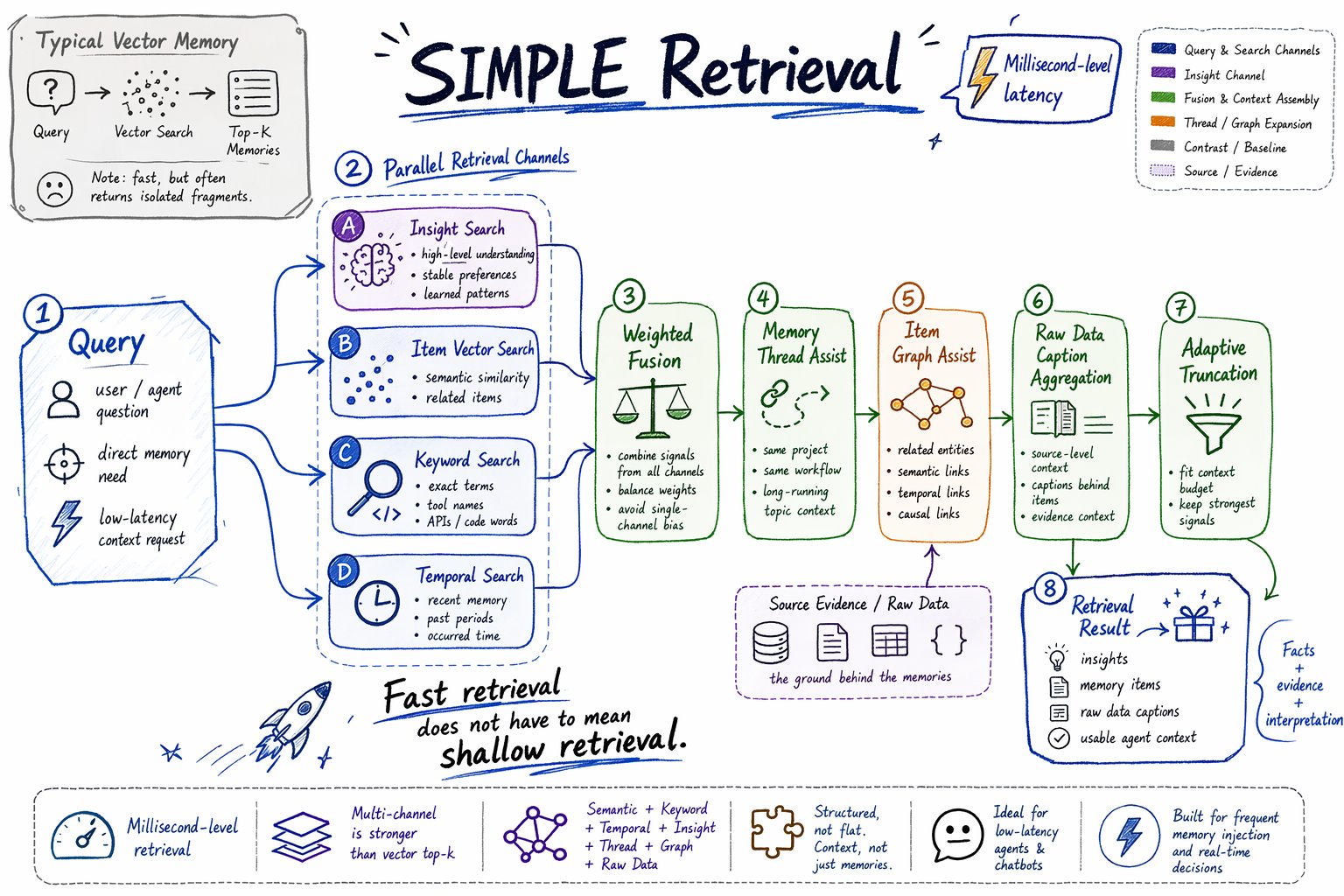
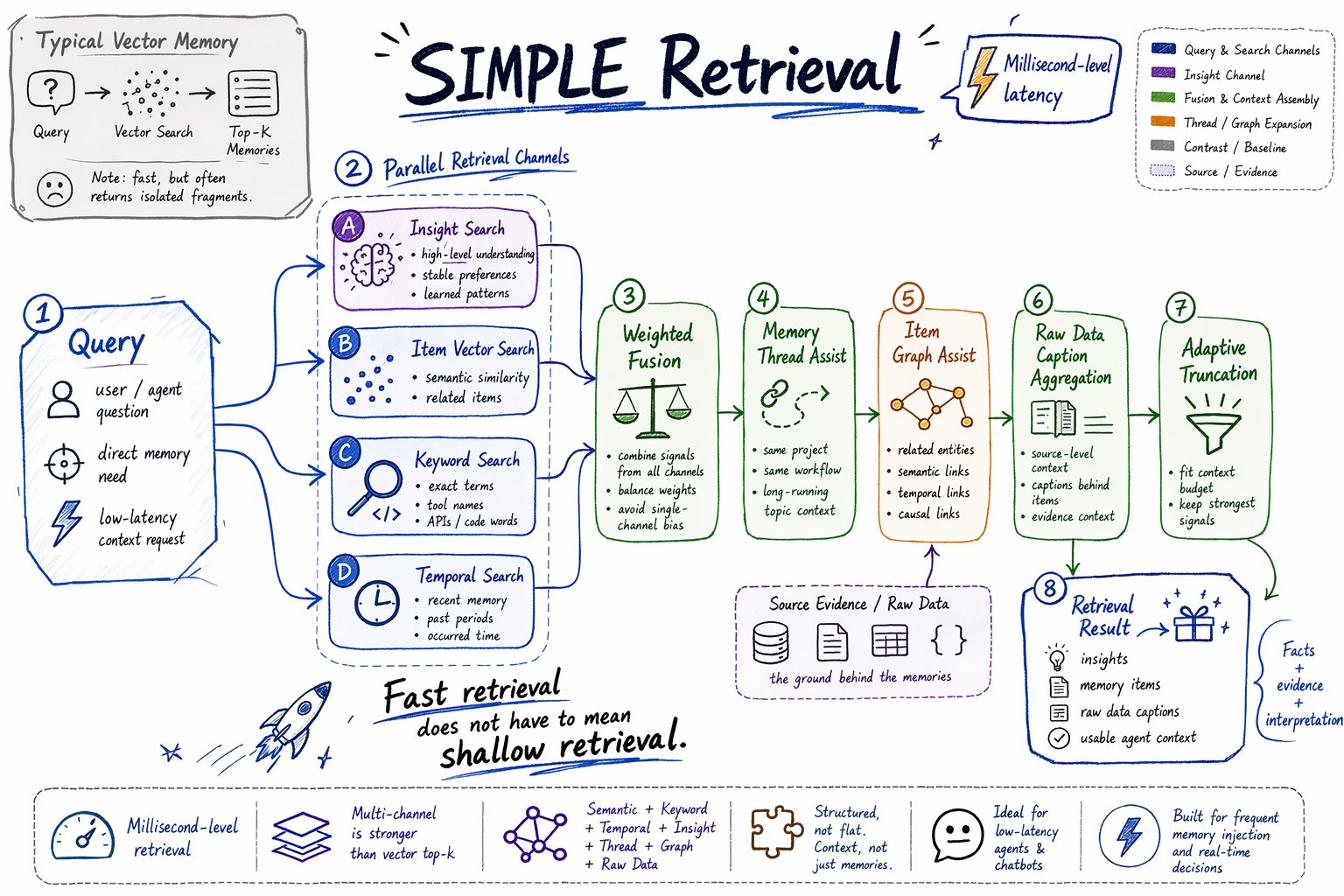
SIMPLE retrieval is the low-latency retrieval path.
It is designed for millisecond-level memory recall in agents and chatbots that need to retrieve memory before many responses or tool actions.
SIMPLE is not plain vector top-k. It runs multiple retrieval channels and fuses their results.
How SIMPLE works
At a high level,SIMPLE retrieval follows this flow:
| Channel | Role |
|---|---|
| Insight vector search | Finds high-level understanding from the Insight Tree. |
| Item vector search | Finds semantically similar memory items. |
| Item keyword search | Finds exact terms through keyword/BM25 search. |
| Temporal item search | Adds time-aware candidates when the query contains temporal intent. |
| Memory thread assist | Pulls related items from long-running topics. |
| Graph assist | Expands from direct hits to related graph-connected memory. |
Why SIMPLE is useful
SIMPLE gives agents fast memory recall without relying on a heavier reasoning path.
It improves over plain vector search because each channel covers a different failure mode:
| Problem | How SIMPLE helps |
|---|---|
| Semantic search misses exact technical terms. | Keyword search can match names, APIs, tools, and code terms. |
| Keyword search misses paraphrased meaning. | Vector search can find semantically similar memory. |
| Top-k returns isolated facts. | Graph and thread assist can add related context. |
| A query depends on time. | Temporal retrieval can use occurred time and time constraints. |
| Items are too terse. | Raw Data captions add source-level context. |
| One channel dominates results. | Weighted fusion combines signals from multiple channels. |
SIMPLE when retrieval should be fast but still memory-aware.
When to use SIMPLE
UseSIMPLE for:
- millisecond-level memory recall
- normal chat turns
- low-latency agent loops
- direct fact or preference lookup
- retrieving recent or obvious context
- applications where retrieval runs often
- cases where you want strong recall without extra deep-retrieval cost
DEEP retrieval
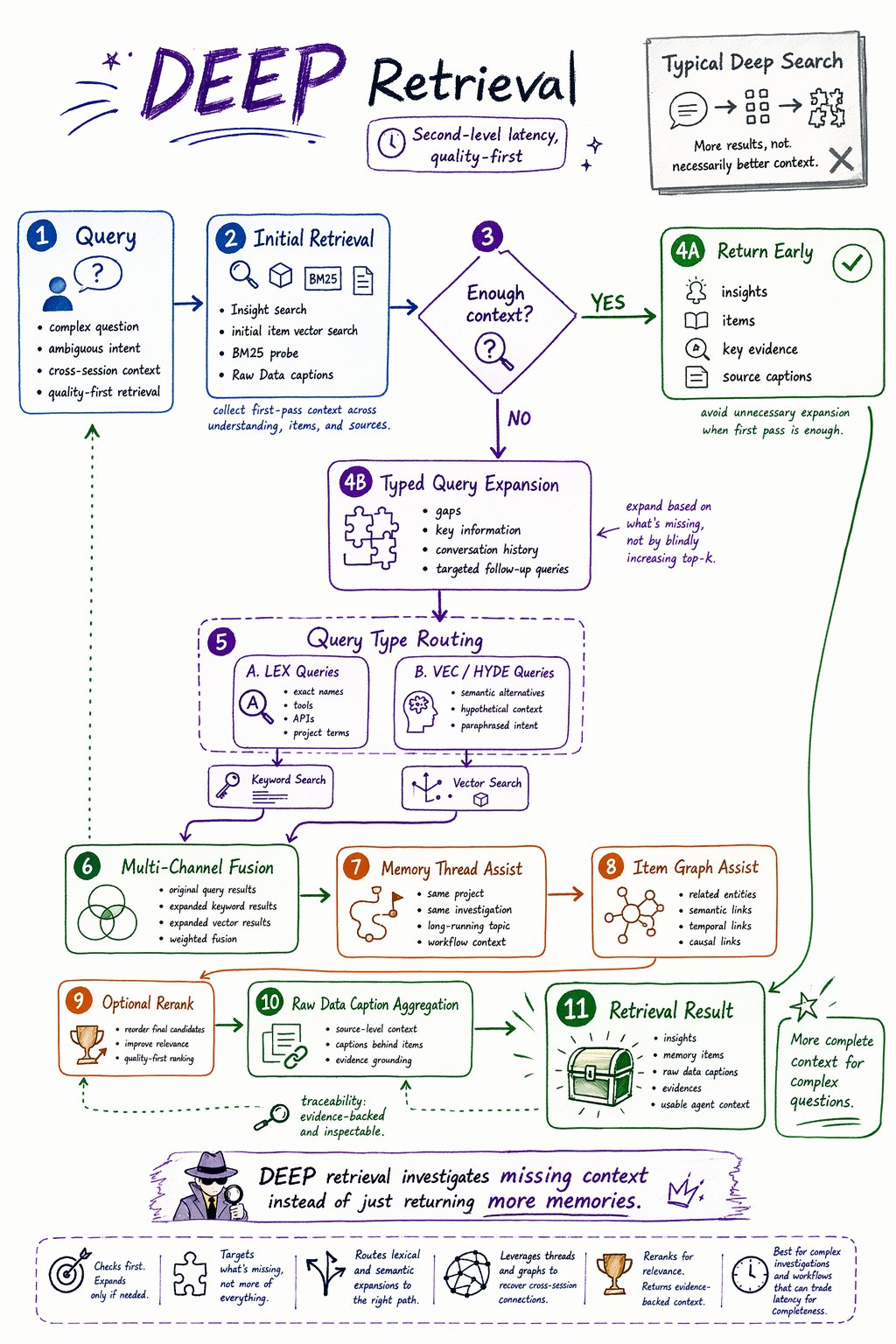
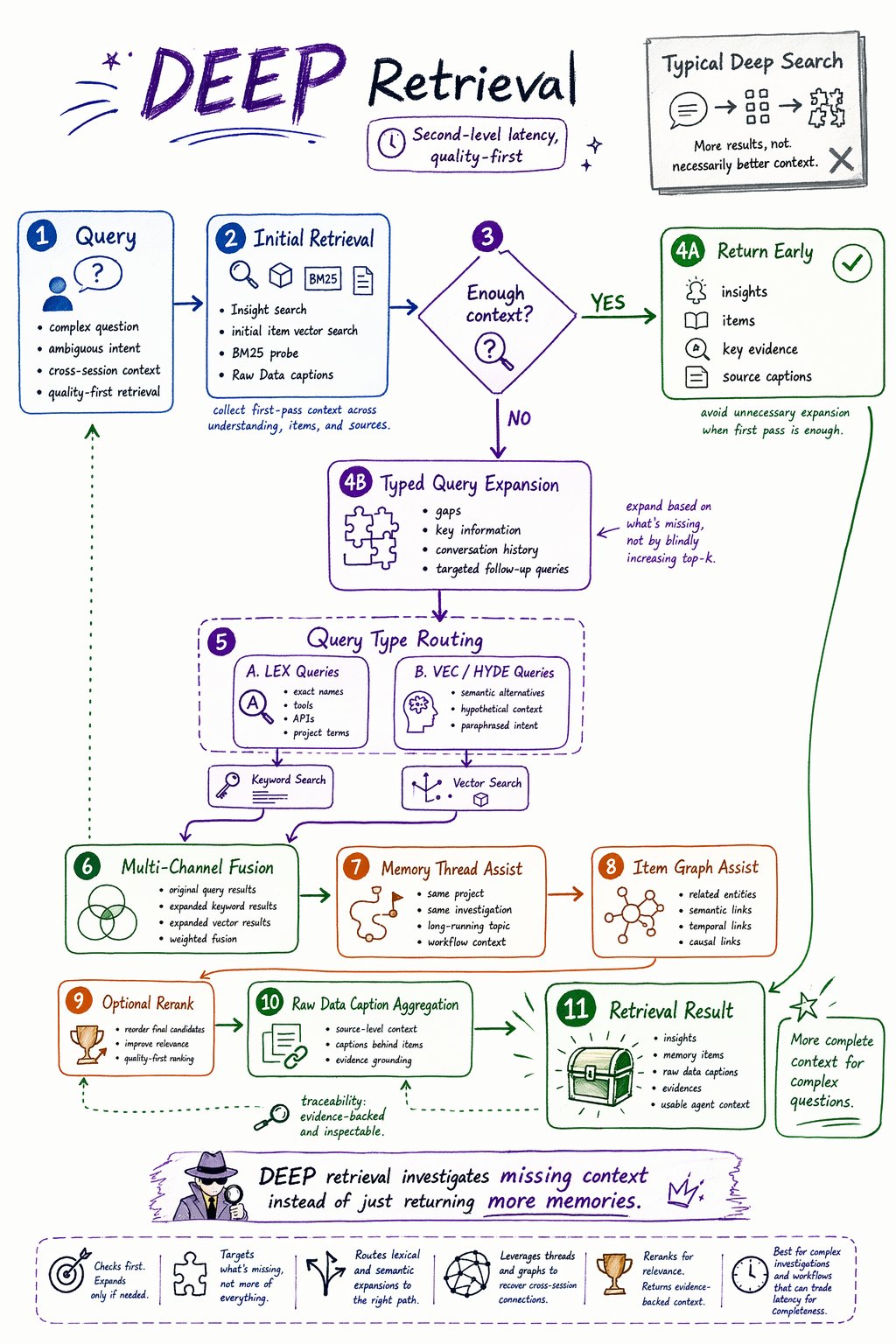
DEEP retrieval is the quality-first retrieval path.
It is designed for second-level retrieval latency, where the application can spend more time to get broader evidence, better recall, and higher-quality context.
DEEP is useful for harder questions: ambiguous queries, cross-session investigations, project-level questions, or cases where the agent needs stronger evidence before acting.
DEEP does not simply increase top-k. It first checks whether the initial context is sufficient. If not, it expands the search intelligently.
How DEEP works
At a high level,DEEP retrieval follows this flow:
Why DEEP is useful
DEEP helps when the first search pass does not provide enough context.
| Capability | Why it matters |
|---|---|
| Sufficiency check | Avoids unnecessary expansion when the initial result is already enough. |
| Typed query expansion | Generates targeted follow-up queries instead of only increasing top-k. |
LEX routing | Sends keyword-style expansions to keyword search. |
VEC / HYDE routing | Sends semantic expansions to vector search. |
| Thread assist | Finds related context inside long-running topics. |
| Graph assist | Expands through relationships between memory items. |
| Optional rerank | Improves final ordering for complex queries. |
| Evidence output | Returns key evidence when the initial context is sufficient. |
DEEP useful for retrieval quality, not just retrieval quantity.
When to use DEEP
UseDEEP for:
- second-level retrieval where quality matters more than latency
- ambiguous user questions
- cross-session memory search
- project or investigation questions
- queries that need broader evidence
- cases where missing context is expensive
- tasks where retrieval quality matters more than latency
SIMPLE vs DEEP
Use this table as a practical guide.| Need | Recommended strategy |
|---|---|
| Millisecond-level memory recall | SIMPLE |
| Low-latency chatbot responses | SIMPLE |
| Memory retrieval before frequent agent actions | SIMPLE |
| Direct user preference lookup | SIMPLE |
| Exact technical term or tool lookup | SIMPLE |
| Second-level retrieval is acceptable | DEEP |
| Retrieval quality matters more than latency | DEEP |
| Need more complete evidence | DEEP |
| Ambiguous or underspecified query | DEEP |
| Cross-session investigation | DEEP |
| Project-level context reconstruction | DEEP |
SIMPLE is the default retrieval mode. Use DEEP selectively for harder questions.
What retrieval returns
Memind retrieval returns a structured result, not just a flat list.| Output | Meaning |
|---|---|
insights | High-level understanding from the Insight Tree. |
items | Structured memory items ranked by retrieval score. |
rawData | Aggregated Raw Data captions behind retrieved items. |
evidences | Key evidence produced by deep retrieval when available. |
strategy | The retrieval strategy used. |
query | The effective query used for retrieval. |
| Layer | Role |
|---|---|
| Insights | Provide interpretation. |
| Items | Provide concrete facts and memory units. |
| Raw Data captions | Provide source-level context. |
Retrieval traces
Memory retrieval can be difficult to debug. Memind provides retrieval traces so developers can inspect what happened during retrieval. A trace can help answer questions like:- Was
SIMPLEorDEEPused? - Which retrieval channels ran?
- Did keyword search return candidates?
- Did temporal retrieval activate?
- Did graph assist or memory-thread assist change the result?
- Did
DEEPtrigger query expansion? - Was reranking applied?
- Why did a specific item appear in the final result?
Configuration
Retrieval behavior can be controlled through runtime configuration. Common configuration areas include:| Area | Controls |
|---|---|
| Strategy | Whether to use SIMPLE or DEEP. |
| Tier limits | How many insights, items, and Raw Data captions to retrieve. |
| Fusion scoring | How vector, keyword, temporal, graph, and thread signals are weighted. |
| Temporal retrieval | Whether time-aware retrieval is enabled. |
| Graph assist | Whether related graph-connected memory can be added. |
| Memory thread assist | Whether long-running topic context can be added. |
| Deep retrieval | Sufficiency checking, query expansion, and reranking behavior. |
| Trace | Whether retrieval traces are collected for debugging. |
| Cache | Whether repeated retrieval requests can reuse cached results. |