Overview
A Memory Item is not a raw message, a text chunk, or a source document. It is a structured memory unit extracted from source context. Each item is concise enough to retrieve and reuse, but still linked back to the Raw Data that produced it. Memory Items help Memind answer:What should be remembered from this source context?This is the bridge between source evidence and usable memory.
Why Memory Items exist
Raw Data is useful because it preserves context, but it is still close to the original source. Agents usually need a more compact and durable form of memory. They need to know the user’s stable preferences, current projects, past decisions, tool experience, reusable workflows, and resolved problems without reading the full source context every time. Memory Items provide that layer. They let Memind:- extract durable memory from broader source context
- separate user memory from agent operating memory
- classify memory into meaningful categories
- preserve temporal meaning when memory is time-bound
- extract optional foresight for likely future needs
- deduplicate repeated facts
- index structured memory for retrieval
- connect items through the Item Graph
- group items into Memory Threads
- consolidate items into Insights
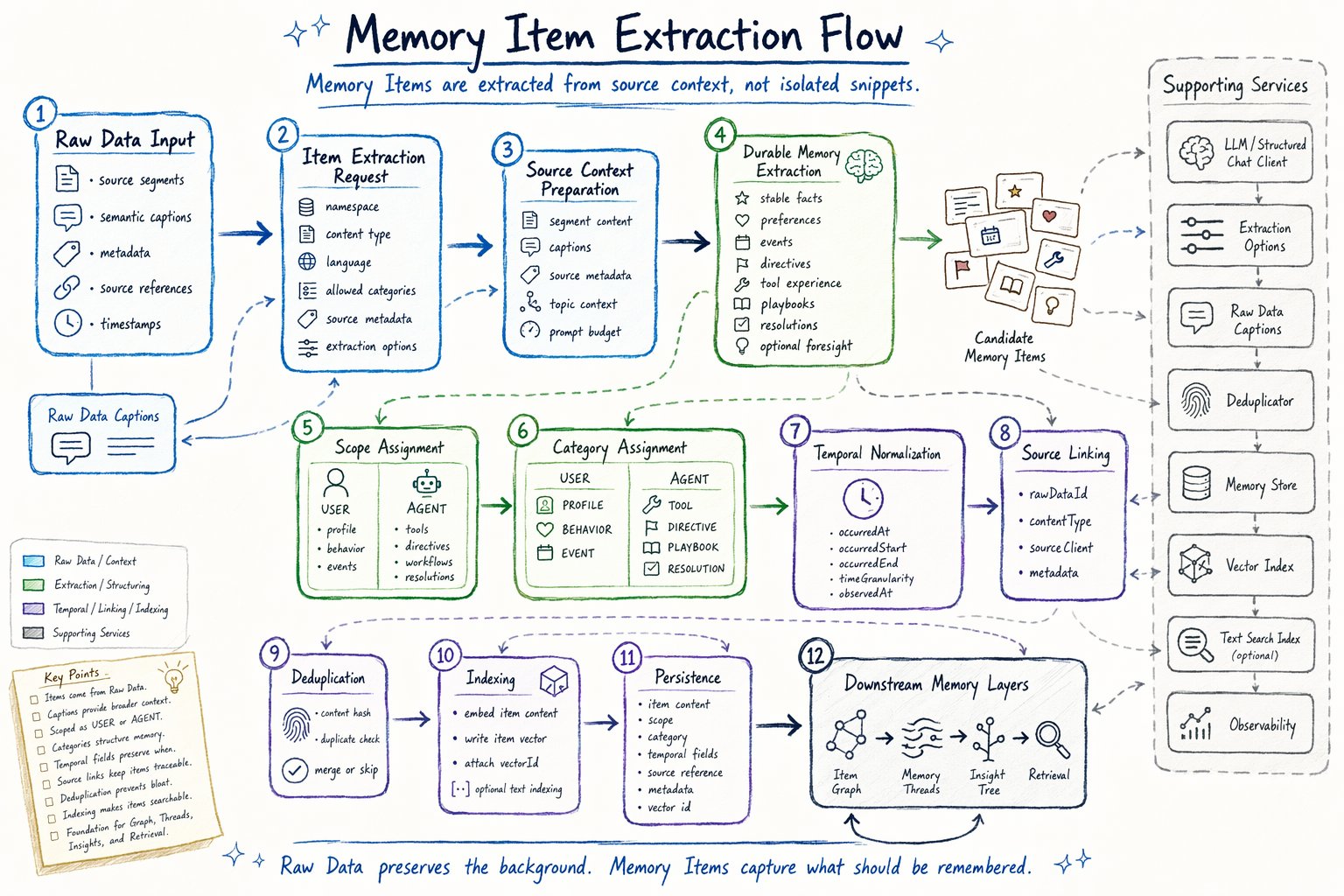
Extraction flow
Memory Item extraction starts from Raw Data. At a high level, the flow is:| Step | Purpose |
|---|---|
| Raw Data Input | Start from source segments, semantic captions, metadata, references, and timestamps. |
| Item Extraction Request | Prepare namespace, content type, language, allowed categories, metadata, and extraction options. |
| Source Context Preparation | Use segment content, Raw Data captions, metadata, and topic context to avoid extracting from isolated snippets. |
| Durable Memory Extraction | Extract concise memory candidates that should be useful beyond the immediate message. |
| Scope Assignment | Separate USER memory from AGENT memory. |
| Category Assignment | Assign structured memory categories such as PROFILE, EVENT, DIRECTIVE, or PLAYBOOK. |
| Temporal Normalization | Preserve when the memory happened, what interval it covers, or when it was observed. |
| Source Linking | Link each item back to the Raw Data that produced it. |
| Deduplication | Avoid endlessly appending repeated memory. |
| Indexing | Make items searchable through vector and optional text indexes. |
| Persistence | Store durable structured memory items. |
| Downstream Memory Layers | Feed the Item Graph, Memory Threads, Insight Tree, and Retrieval. |
Memory Item records
A Memory Item stores structured information about one durable memory unit. Conceptually, it contains:| Field | Meaning |
|---|---|
id | Unique item identifier. |
memoryId | The memory namespace this item belongs to. |
content | The durable memory text. |
scope | Whether the item belongs to USER or AGENT memory. |
category | The structured memory category. |
contentType | The source content type, such as conversation content. |
sourceClient | The client or integration that produced the source. |
vectorId | The vector index ID for item retrieval. |
rawDataId | The Raw Data record that produced this item. |
contentHash | A fingerprint used for deduplication. |
occurredAt | The semantic occurrence time, when available. |
occurredStart | The normalized lower bound for a time interval. |
occurredEnd | The normalized upper bound for a time interval. |
timeGranularity | The precision of the normalized time. |
observedAt | When the source segment was observed. |
metadata | Extra structured metadata. |
createdAt | When the item was created. |
type | The item type, such as FACT or FORESIGHT. |
Scopes
Memind separates memory into two scopes:USER and AGENT.
| Scope | Meaning |
|---|---|
USER | Memory about the user: who they are, what they prefer, what they do, and what is happening in their world. |
AGENT | Memory for the agent: how it should behave, how tools worked, reusable workflows, and resolved problems. |
Categories
Each Memory Item belongs to a category. Categories give memory structure. They help Memind filter, group, retrieve, connect, and consolidate items.USER categories
| Category | Meaning |
|---|---|
PROFILE | Stable facts about who the user is, such as role, skills, identity, or enduring preferences. |
BEHAVIOR | Recurring habits, routines, and repeated patterns. |
EVENT | Time-bound situations, actions, decisions, plans, current projects, or past occurrences. |
| Item | Category |
|---|---|
| The user is a Java developer. | PROFILE |
| The user usually prefers stable tooling. | BEHAVIOR |
| The user is migrating a service to Java 21. | EVENT |
AGENT categories
| Category | Meaning |
|---|---|
TOOL | Usage experience and optimization for a specific tool. |
DIRECTIVE | Durable instructions, boundaries, and collaboration rules for the agent. |
PLAYBOOK | Reusable workflows and task-handling patterns. |
RESOLUTION | Resolved problem knowledge with usable fixes or conclusions. |
| Item | Category |
|---|---|
| Use a specific tool option when analyzing a certain repository. | TOOL |
| Show a plan before making substantial edits. | DIRECTIVE |
| For documentation design, first confirm the page structure, then write the MDX. | PLAYBOOK |
| A previous issue was fixed by changing the retrieval graph assist configuration. | RESOLUTION |
Item types
Memory Items can have different item types.| Type | Meaning |
|---|---|
FACT | A factual memory extracted from source context. |
FORESIGHT | An optional forward-looking memory inferred from conversation signals. |
FACT items. They describe something that is true, happened, is happening, or should be reused.
FORESIGHT items are different. They capture useful future-facing signals that may help the agent prepare for what the user is likely to need next.
Foresight items
Foresight lets Memind store forward-looking memory. AFORESIGHT item is not a confirmed fact in the same way a FACT item is. It is a predictive or anticipatory memory derived from conversation signals.
For example, if a user repeatedly discusses migrating a Java service, stabilizing tooling, and preparing documentation, Memind may infer foresight such as:
- upcoming user needs
- likely follow-up tasks
- possible project risks
- expected tool usage
- preparation hints for future sessions
- inferred next-step context
| Quality | Meaning |
|---|---|
| Grounded | It should be based on observed conversation signals. |
| Useful | It should help the agent prepare or retrieve better context later. |
| Non-authoritative | It should not be treated as a confirmed user fact. |
| Revisable | It should be allowed to become stale or be replaced as new context arrives. |
FORESIGHT extraction is optional and depends on runtime configuration.
Temporal information
Not every memory has the same relationship to time. Some memory is stable:| Field | Meaning |
|---|---|
occurredAt | A point-in-time semantic occurrence. |
occurredStart | The start of a normalized time interval. |
occurredEnd | The end of a normalized time interval. |
timeGranularity | Whether the time is day-level, month-level, or another precision. |
observedAt | When the source content was observed. |
Source references
A Memory Item should not be disconnected from its origin. Each item can keep arawDataId that links it back to the Raw Data record that produced it.
This matters because Raw Data carries the broader source context behind the item:
- where the item came from
- what source segment produced it
- what topic context surrounded it
- whether extraction was accurate
- whether the item should be kept, corrected, or ignored
Deduplication
Memory systems can easily grow noisy if they keep appending the same fact. Memind uses content fingerprints to help detect repeated items. Deduplication helps avoid cases like:Indexing
Memory Items are searchable. After extraction, item content can be embedded and stored in a vector index. The item keeps avectorId so it can participate in semantic retrieval.
This is separate from Raw Data and Insight indexing.
| Indexed layer | What is embedded |
|---|---|
| Raw Data | Segment captions. |
| Memory Items | Structured memory item content. |
| Insights | Consolidated insight content. |
- source evidence from Raw Data
- durable structured memory from Memory Items
- higher-level patterns from Insights
Relationship to other layers
Memory Items are the foundation for several later layers.| Layer | Relationship |
|---|---|
| Raw Data | Items are extracted from Raw Data and keep source references. |
| Item Graph | Items become connected through entities, aliases, mentions, semantic links, temporal links, and co-occurrence. |
| Memory Threads | Related items are grouped into long-running topic projections. |
| Insight Tree | Items are consolidated into higher-level LEAF, BRANCH, and ROOT insights. |
| Retrieval | Items are direct retrieval candidates and can be returned with evidence and traces. |
Inspecting Memory Items
Memind UI lets developers inspect Memory Items. This is useful when you want to understand:- what memory was extracted
- which scope and category were assigned
- whether temporal fields were normalized correctly
- which Raw Data record produced the item
- whether the item has a vector index reference
- what metadata was attached
- whether repeated memory is being deduplicated
- how items connect to downstream graph, thread, and insight layers
Common use cases
Memory Items support several common agent memory workflows.| Use case | Why Memory Items help |
|---|---|
| Personalization | Store stable user facts and durable preferences. |
| Project continuity | Remember current projects, decisions, plans, and constraints. |
| Temporal recall | Preserve past events, current situations, and future intentions. |
| Agent instructions | Keep durable directives about how the agent should behave. |
| Tool learning | Remember tool usage experience and configuration knowledge. |
| Reusable workflows | Store playbooks for repeated task patterns. |
| Problem solving | Preserve resolved problems and reusable fixes. |
| Forward-looking assistance | Store foresight signals that help the agent prepare for likely next steps. |
| Graph and insight building | Provide structured nodes for relationships, threads, and higher-level insights. |