Raw Data keeps memory grounded in source context.
Overview
Raw Data is not just archived input. It is the source layer behind Memind’s structured memory system. Each Raw Data record preserves a source segment, its metadata, source references, timing information, and a generated caption. That caption is important. It turns a raw source segment into a compact semantic context that can be searched, inspected, and used to understand the background behind extracted Memory Items. A Memory Item tells Memind what durable memory was extracted. Raw Data tells Memind where that memory came from and what broader context shaped it.Why Raw Data exists
Many memory systems jump directly from conversation text to extracted facts. That works for simple preferences, but it often loses the surrounding context. An agent may retrieve several correct items, but still miss the larger situation that produced them. For example, the agent might retrieve:- the user uses Java 21
- the user prefers stable tools
- the user is migrating a service
- source context before higher-level memory is extracted
- traceability from Memory Items back to observed content
- searchable captions for source-level evidence
- a way to recover broader context behind isolated items
- an inspection layer for debugging memory quality
- a stable foundation for future processing and reprocessing
Why captions matter
Raw Data captions are not just summaries. In Memind, source content can be segmented around meaningful context boundaries, such as a topic, workflow, decision, incident, or conversation shift. For conversation content, LLM-based segmentation can identify these semantic boundaries instead of relying only on arbitrary fixed-size chunks. That means a Raw Data segment can represent a coherent slice of context. The caption then becomes a compact semantic handle for that segment. This matters because Memory Items are intentionally concise. They capture durable facts, preferences, events, directives, tool experience, playbooks, or resolutions. But an item alone may not carry the full background of the conversation that produced it. Raw Data captions keep that background searchable. Instead of retrieving only scattered items, Memind can also retrieve the source-level context behind those items:Where Raw Data fits
Raw Data is created early in the memory construction flow.| Layer | How it uses Raw Data |
|---|---|
| Memory Items | Extract durable facts, preferences, events, directives, tool experience, playbooks, and resolutions from Raw Data. |
| Item Graph | Connects extracted items that keep source references back to Raw Data. |
| Memory Threads | Groups related items that were originally extracted from Raw Data. |
| Insight Tree | Consolidates higher-level understanding from items while preserving evidence through item and source references. |
| Retrieval | Can return raw-data captions and source evidence alongside structured memory results. |
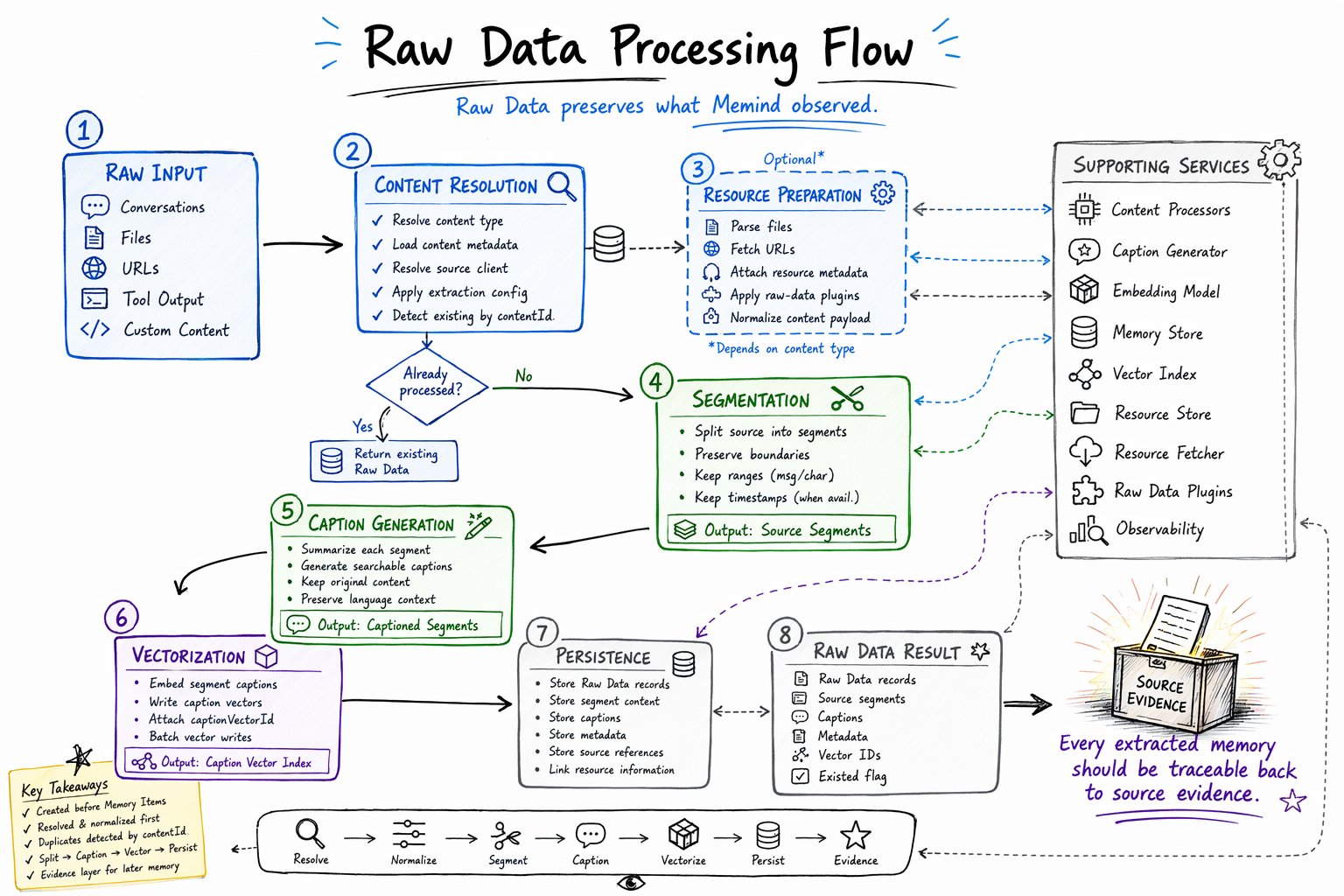
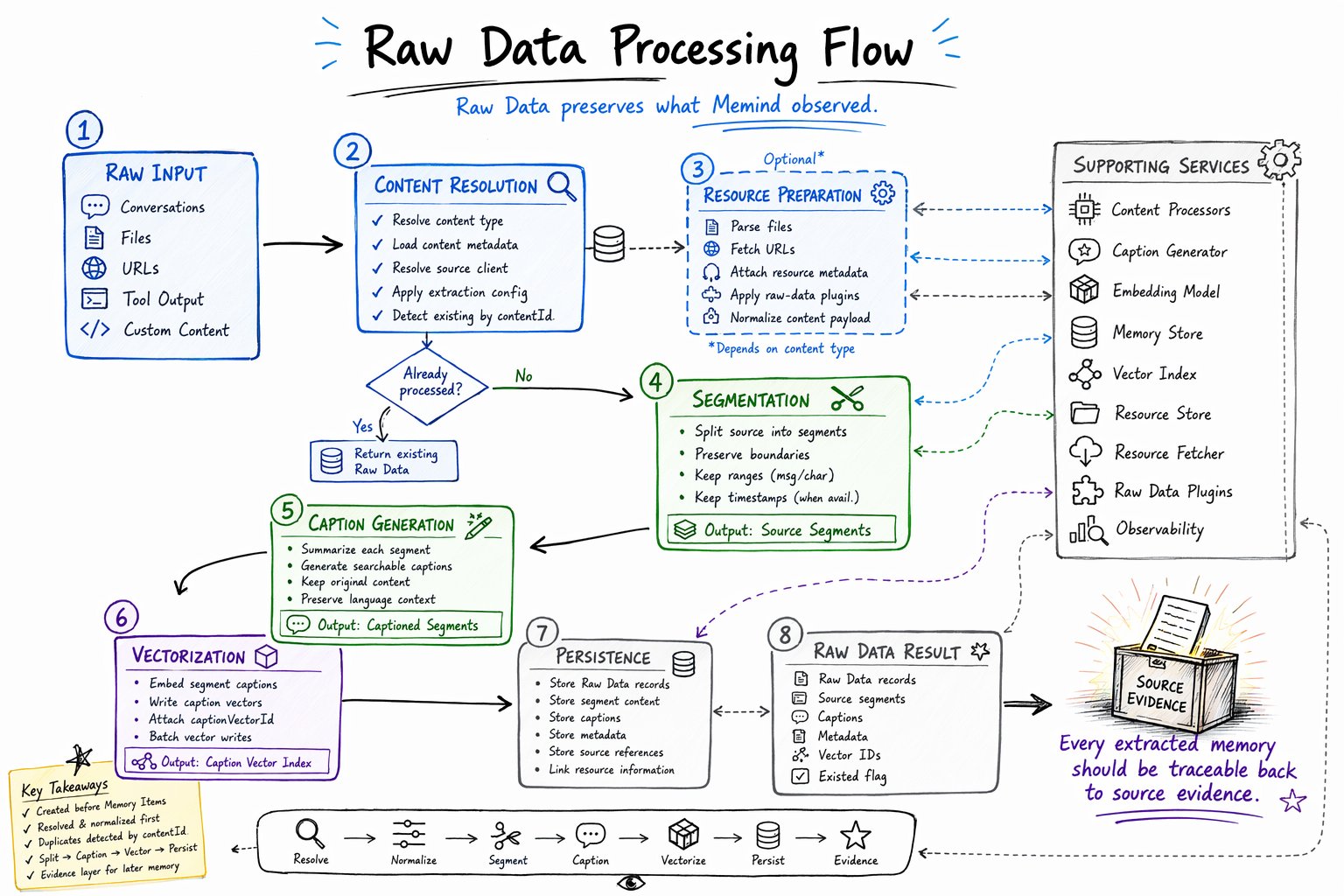
Processing flow
Raw Data processing turns raw input into source-level records. At a high level, the flow is:| Step | Purpose |
|---|---|
| Content Resolution | Resolve content type, metadata, source client, extraction config, and content identity. |
| Resource Preparation | Parse files, fetch URLs, apply plugins, and normalize the source payload when needed. |
| Segmentation | Split source content into meaningful, inspectable units with boundaries and source timing. |
| Caption Generation | Generate semantic captions for source segments. |
| Vectorization | Embed captions and store vector IDs for source-level retrieval. |
| Persistence | Store Raw Data records with segments, captions, metadata, references, and timestamps. |
| Raw Data Result | Return Raw Data records and source segments to the next construction stage. |
Raw Data records
A Raw Data record stores source-level information about one processed segment. Conceptually, it contains:| Field | Meaning |
|---|---|
id | Unique Raw Data segment identifier. |
memoryId | The memory namespace this Raw Data belongs to. |
contentType | The type of source content, such as conversation content. |
sourceClient | The client or integration that produced the content. |
contentId | A content fingerprint used for idempotency. |
segment | The source segment, including content, boundary, and metadata. |
caption | A compact semantic summary of the segment. |
captionVectorId | The vector index ID for the caption embedding. |
metadata | Additional source or application metadata. |
resourceId | Optional reference to a stored resource. |
mimeType | Optional MIME type for file or resource content. |
createdAt | When the Raw Data record was created. |
startTime | Source start time when available. |
endTime | Source end time when available. |
Segments
A segment is the source unit that Raw Data persists. For conversation content, a segment may represent a range of messages. For other content types, it may represent a character range, parsed section, or processor-defined chunk. A segment can include:| Segment field | Meaning |
|---|---|
content | The source text for this segment. |
caption | The generated semantic summary for the segment. |
boundary | The source boundary, such as message range or character range. |
metadata | Segment-level metadata. |
Captions
Captions summarize Raw Data segments into compact semantic context. A caption does not replace the original content. It gives the segment a searchable and human-readable representation. Captions are useful because they:- make source segments easier to browse in Memind UI
- provide compact source-level retrieval text
- reduce noise when searching Raw Data
- help LLMs understand the background behind extracted items
- preserve a semantic view of the original source segment
- provide text that can be embedded for vector search
Metadata and source references
Raw Data can carry source metadata and references. This is useful when memory comes from multiple applications, agents, files, URLs, or tools. Common metadata and references include:| Concept | Purpose |
|---|---|
sourceClient | Identifies which client, integration, or application produced the content. |
contentType | Describes how the content should be processed. |
resourceId | Links Raw Data back to a stored resource. |
mimeType | Preserves resource type information for files or external content. |
startTime / endTime | Preserves the time range represented by the source segment. |
metadata | Carries application-specific source information. |
Vector indexing
Raw Data can be indexed for semantic search. Memind vectorizes Raw Data captions and stores the resulting vector IDs on Raw Data records. This allows source-level evidence to participate in retrieval without embedding the entire original content as the only searchable representation. Raw Data vector indexing is separate from Memory Item and Insight indexing.| Indexed layer | What is embedded |
|---|---|
| Raw Data | Segment captions. |
| Memory Items | Structured memory item content. |
| Insights | Consolidated insight content. |
Idempotency
Raw Data processing uses content identity to avoid duplicate work. Each raw input can produce acontentId, which acts as a fingerprint of the original content. Before processing, Memind can check whether the same content has already been stored for the same memory namespace.
If the content already exists, Memind can return the existing Raw Data instead of writing duplicate source records.
This is useful when:
- the same conversation batch is submitted more than once
- ingestion is retried after a failure
- integrations resend previously observed content
- applications want safer repeated writes
Relationship to Memory Items
Raw Data is the input evidence for Memory Item extraction. After Raw Data is created, Memind extracts structured Memory Items from it. Those items can keep references back to the Raw Data record that produced them. This relationship is important:- Memory Items provide concise durable facts.
- Raw Data captions provide the broader context behind those facts.
Inspecting Raw Data
Memind UI lets developers inspect the Raw Data layer. The Raw Data view is useful when you want to understand:- what source content was ingested
- how content was segmented
- what captions were generated
- which source client produced the data
- what metadata was attached
- what time range the source segment represents
- whether downstream memory came from the expected source
- what broader context sits behind a Memory Item
Common use cases
Raw Data is useful in several development workflows:| Use case | Why Raw Data helps |
|---|---|
| Debug extraction | Check whether a Memory Item came from the expected source context. |
| Audit memory quality | Inspect source segments when extracted memory looks wrong or incomplete. |
| Improve ingestion | See how conversations, files, or custom content are segmented and captioned. |
| Trace retrieval evidence | Understand which source segments support a retrieved context. |
| Recover background context | Retrieve the broader topic context behind concise Memory Items. |
| Extend content support | Validate custom parsers, resource fetchers, and Raw Data plugins. |